
Python CSV 파일을 오픈할 때 UnicodeDecodeError: utf-8 또는 cp949 codec can’t decode byte 나는 경우가 있습니다.
이럴 때, 어떻게 처리하는지 알아보겠습니다.
해결방법1 : open시 encoding 지정
우선, notepad++가 필요합니다.
아래 주소에서 다운해주세요.
https://notepad-plus-plus.org/downloads/
이제 python에서 오픈하려는 파일을 notepad++로 열어보면,
우측 아래에 ANSI / UTF-8 인지 나옵니다.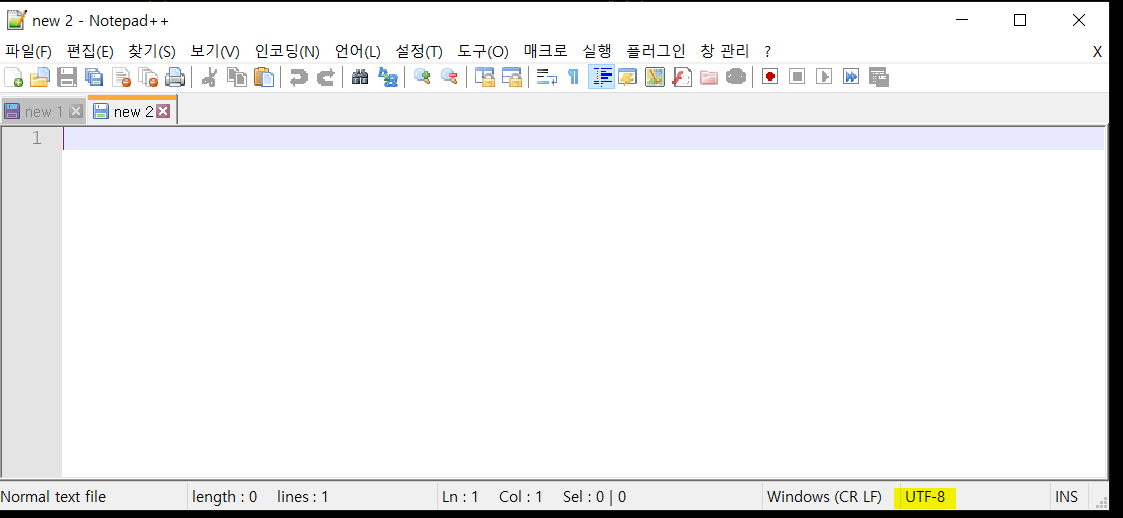
ANSI라면, 아래와 같이 encoding=’cp949’를 지정해서 파이썬에서 파일을 오픈합니다.
1 | open(file_name, 'w', encoding='cp949') |
UTF-8이라면, 아래와 같이 파이썬에서 파일을 오픈합니다.
1 | open(file_name, 'w', encoding='utf-8') |
해결방법2 : 파일의 인코딩 변경
이 해결방법 역시 notepad++가 필요합니다.
notepad++로 파일을 열어서, 다른이름으로 저장 > 적절한 인코딩을 선택하여 저장하면 됩니다.
해결방법3 : 파일의 인코딩을 바꿀 수 없는 상황이면서, 어떤 인코딩의 파일이 들어올지 모를 경우
파일의 인코딩을 바꿀 수 없는 상황이면서, 어떤 인코딩의 파일이 들어올지 모를 경우,
아래와 같이 인코딩 정하지 않고 그냥 한번 읽어본 다음에 chardet.detect() 로 인코딩을 확인할 수 있습니다.
1 | bytes = min(32, os.path.getsize(filename)) |
파이썬에서 UnicodeDecodeError: utf-8 또는 cp949 codec can’t decode byte 에러가 뜨는 원인
텍스트 파일을 읽는 프로그램(Notepad++, Editplus, VsCode, PyCharm 등)에서는 파일을 읽어보고
UTF-8 파일인지, EUC-KR(CP949)인지 판단하는데요.
Python의 기본 open 함수는 인코딩을 따로 판단하지 않습니다.
open 함수는 지정한 문자 인코딩만 생각하고 파일을 열기때문에,
다른 인코딩의 문자들이 들어오면, 제대로 문자를 못읽고 에러가 발생하는 것입니다.
python,csv,cp949,unicodedecodeerror